Gauntlet Data Set: Mirror Matches
 Xoiiku
✭✭✭✭
Xoiiku
✭✭✭✭
in The Bridge
Moving this over from the old forums as it might be helpful to the ongoing Gauntlet conversations.
I've been reading and skimming most of the threads on possibility of shenanigans and/or rigging in the Gauntlet. Early on in the discussion, I thought it might be useful to compile a data set of only mirror matches in order to try to simplify the number of potential variables, attempt to control for selection bias and confirmation bias, such that we might get a bit more signal through the noise.
That said, I do not have a strong enough knowledge of statistics to offer any conclusion as to the possibility of rigging and that is not my intent. My purpose was simply to gather some data and to mention the probable influences of cognitive bias and logical fallacies (such as Gambler's fallacy).
For that part of it, I suggest the perspective that cognitive bias is to thinking what optical illusions are to seeing, and that the first step in avoiding a trap, is knowing of it's existence.
In terms of the mirror match data:
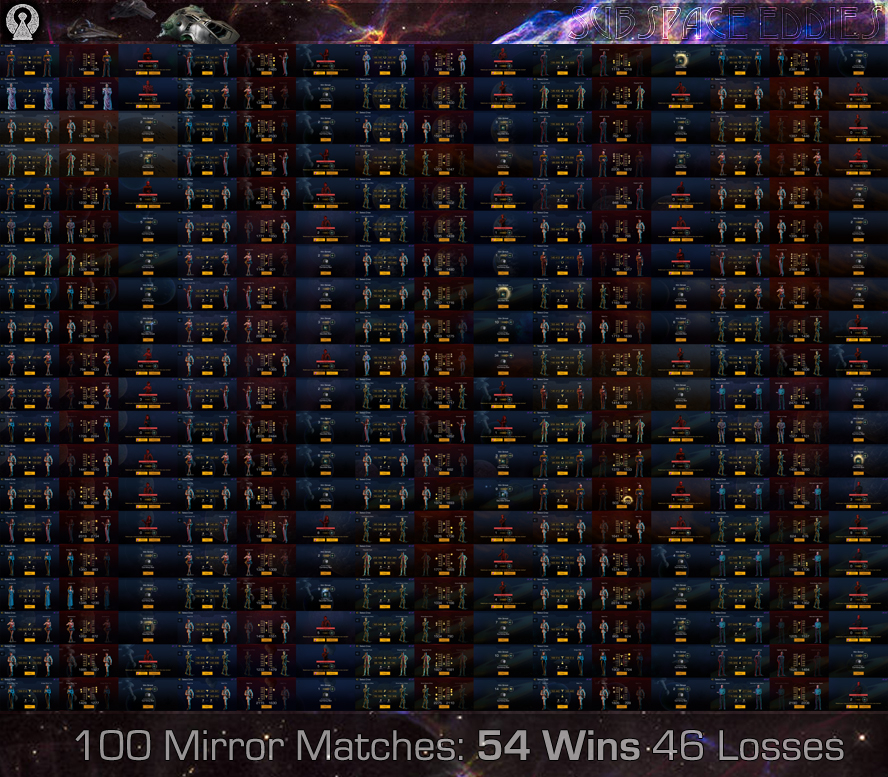
So, hopefully that is useful to somebody. I think it might be cool to have other people gather some mirror match data, if such was found to be helpful for moving this discussion forward. For myself, I burned through a lot of time, merits and jeopardized possible streaks gathering this data. I found it to be an interesting exploration if nothing else, particularly in terms of my own negativity bias (despite being aware of and looking out for it). I'd recommend at least gathering some of your own data for anyone who has a strong opinion on the matter.
My impression is that with 54 wins out of 100 matches, it's basically inconclusive or a null result in terms of any evidence of shenanigans... unless they knew I was gathering this data...
There is a spreadsheet version linked in the old thread for those interested.
I've been reading and skimming most of the threads on possibility of shenanigans and/or rigging in the Gauntlet. Early on in the discussion, I thought it might be useful to compile a data set of only mirror matches in order to try to simplify the number of potential variables, attempt to control for selection bias and confirmation bias, such that we might get a bit more signal through the noise.
That said, I do not have a strong enough knowledge of statistics to offer any conclusion as to the possibility of rigging and that is not my intent. My purpose was simply to gather some data and to mention the probable influences of cognitive bias and logical fallacies (such as Gambler's fallacy).
For that part of it, I suggest the perspective that cognitive bias is to thinking what optical illusions are to seeing, and that the first step in avoiding a trap, is knowing of it's existence.
In terms of the mirror match data:
So, hopefully that is useful to somebody. I think it might be cool to have other people gather some mirror match data, if such was found to be helpful for moving this discussion forward. For myself, I burned through a lot of time, merits and jeopardized possible streaks gathering this data. I found it to be an interesting exploration if nothing else, particularly in terms of my own negativity bias (despite being aware of and looking out for it). I'd recommend at least gathering some of your own data for anyone who has a strong opinion on the matter.
My impression is that with 54 wins out of 100 matches, it's basically inconclusive or a null result in terms of any evidence of shenanigans... unless they knew I was gathering this data...
There is a spreadsheet version linked in the old thread for those interested.
We are all downstream from each other and ourselves, therefore choose to be relaxed and groovy.
Consider participating in civil discourse, understanding the Tardigrade, and wandering with the Subspace Eddies.
Consider participating in civil discourse, understanding the Tardigrade, and wandering with the Subspace Eddies.
6
Comments
I thought that since some people found the mirror match data set interesting, and possibly useful if not somewhat relevant, that an even better and more useful data set would be mirror mirror matches. Given the fact that a mirror mirror match is 10 times more accurate than a simple mirror match, I therefore only needed 10 matches to have the same statistical significance as the previous 100.
As such, I have done a solid 45 minutes of science and I came to a CONCLUSION:
The Gauntlet is rigged in favor of T'Pol, winning against T'Pol
And here, is my evidence:
Consider participating in civil discourse, understanding the Tardigrade, and wandering with the Subspace Eddies.
IF I'd code a rigged gauntlet, of course I'd exclude my "cheat"code on matches which are to obvious, where most people can easily compare the matches. These are mirror matches. I'd programm a function which determinates how likely the user can compare the outcomes.
For example a mirror match where the Attacker has 400-500 SEC and the defender has 400-500 SEC it is very comparable to the user, to spot an unfairness.
In contrast to:
If the attacker has
123-444 SEC
382-582 ENG
and the defender has
310-718 SEC
313-426 ENG
these are technically also "mirror matches". But they are very uncomparable for a user, most users wouldn't even notice that this are mirror matches.
So, if I were assigned to code a rigged gauntlet, I'd certainly exclude direct mirror matches and instead cheat on the others, this can be accomplished with an unequal roll distribution. That there IS a unequal distribution, that was shown in a player effort by CMV, me and some others, where we collected many datapoints. If it is still there? I don't really know.
Disclaimer: My intention was just to mention what I would do, if I was assigned to code such a thing. I don't want to say that DB has done so. But just to say because obvious mirror matches seem to be fair, to conclude the whole gauntlet must be fair is to easy. Furthermore: DBs devs are also not stupid, if I can think about such a mechanic, they can certainly do as well.
Translation - the lack of evidence of rigging proves that it's rigged.
Disclaimer notwithstanding.
You must be new ^_^
No, seriously, here [1] is the link, so I'd say there is more evidence for the opposite. Next time you could simply ask for the link if you are unable to find it by yourself. Of course I also could have supplied it in my Op.
[1] https://forums.disruptorbeam.com/stt/viewthread/62394/
But that's not the point of my post at all. My point was, whether you meant it or not, a post like that essentially says "if they were to rig it, they wouldn't make it obvious, so the lack of proof is proof itself." It's not a new argument, though this is the first time I've seen it regarding the gauntlet.
Now I'll grant that you're not coming out and making this argument. You're just sort of floating it out there. But that argument is tin foil hattery.
Oh, you now let look me like the new guy it seems. Would you mind point me to that analysis you mentioned? I'm not aware of an equally elaborated and accomplished one like CMVs.
I guess you misinterpreted me or I wasn't clear enough. I felt the sentiment here was that people tend to think that everything must be OK because the mirror matches are. So they take the mirror matches as a proof that everything is OK isn't a proof at all.
I haven't said that the gauntlet is rigged that way I described. That was only an argument or more an explanation to question this result by the Op. Because one thing seems to be sure, there seem to be a discrepancy between the Ops research and the one made by CMV, because I'm very familar to CMVs (because of stated reasons) I think I can exclude he/we made errors. So there has to be another reason why they both differ. One reason is the one I stated, another could of course be, DB changed something. I further stated that I cannot really tell.
Maybe you can think of another explanation why they differ? Just negating something without elaborating on it isn't really helpful.
That's all I have to say on the matter.
I rather call this skepticism, which is the base of all science and progress. Calling it "tin foil hattery" sounds way to offensive. In that regard, Galileo Galilei also had a tin foil, because he questioned some things the "authorities" defined/claimed.
No, I'm bowing out.
The chruch claimed the earth is flat, proofs were shown it wasn't <=> Some player claim the gauntlet is cool, proofs were presented it isn't
I think, if you cannot bring some arguments, then it is really all said on this topic.
Edited: First I said DB claimed everything is cool, but they didn't actually. If the gauntlet IS rigged it is perfectly fine from a legal stance, because they never said otherwise. (The moral stance is another story)
Gauntlet bias data results
Gauntlet Formula Rigged (DB please read and reply)
Am I the only one who thinks the Gauntlet is working just fine?
Gauntlet Data Set: 100 Mirror Matches
There seems to be at least a couple reoccurring arguments for rigging:
1. CMV's data is perceived to conclusively show "There is a distinct defender bias in Gauntlet matches"
2. Mirror match data is invalid because DB hid the rigging for those matches specifically
3. Streak reward thresholds 3,6,9... are treated differently than other matches
I would like to suggest, that however you read the data we have so far, that providing more data or better analysis would be helpful. Particularly, if you have knowledge of how to do statistics properly, which I do not.
If you are having experiences which deviate from either data set (mirror match and general), tracking and documenting it will be more useful than just reporting the "bad beats". It might even be an interesting self study in terms of negativity bias and possibly other logical fallacies. I know collecting data was for me, as even though I was aware of negativity bias and I had my own data telling me that I'd won more than I lost, I still remembered the losses more. Intriguing.
My aim was simply to collect data, and although my impression is that there isn't any rigging, I am not offering any conclusion on that point (except when I think it's funny to do so facetiously and/or satirically as with my mirror mirror post). To the best of my understanding, we would need more data to achieve statistical significance and then we'd need peer review of our data, and then we'd need an independent study done to see if our results were reproducible, before we were in the realm of conclusions.
If you have mirror match only data, and understand why that might be a useful or at least interesting constraint, you can contribute that to this thread, which currently is:
Set 001: Xoiiku | 100 - 54 wins and 46 losses
Set 002: Xoiiku | 10 - 7 wins and 3 losses
Set 003: Deb | 101 - 55 wins and lost 46 losses
Total 211 Matches - 116 wins and 95 losses
If you have general gauntlet data, you can contribute CMV's efforts, though I do not know if they are still collecting data.
Consider participating in civil discourse, understanding the Tardigrade, and wandering with the Subspace Eddies.
The Gambler's Fallacy: Introduction (0/6)
Critical Thinking Part 5: The Gambler's Fallacy
Design of experiments
What Is Confirmation Bias?
Selection bias
On being wrong
Consider participating in civil discourse, understanding the Tardigrade, and wandering with the Subspace Eddies.
If by default we had a counter of our win/loss ratio with a bit of extra info that would help a lot to reduce or remove the perception the Gauntlet is rigged.
A side observation, totally anecdotal, for the past 5 days I only saw a defender with 3 rolls and 25% crit NOT scoring a crit and winning even when the odds were way against it maybe 3 times. And I played the majority of the rounds with the 4 hours interval.
...... people go the lengths because people do exactly what you are doing here, insisting it's broken based on annecdotal evidence. If both front page data collections show it as fair, and you are still citing a random single occurence..... things like these will ultimately keep occuring.